Jekyll2024-09-22T23:11:05-04:00https://willpgfx.com/feed.xmlWillP GFXCode, rendering, otherWill PearceGPU Ray Tracing in an Afternoon2019-10-20T00:00:00-04:002019-10-20T00:00:00-04:00https://willpgfx.com/2019/10/gpu-ray-tracing-in-an-afternoon
It seems to have become something of a rite of passage nowadays for those interested in graphics programming to work their way through Peter Shirley’s excellent Ray Tracing in One Weekend, along the way experiencing firsthand the “aha” moments and the “it’s that simple!?” realizations. With its companions Ray Tracing: The Next Week and Ray Tracing: The Rest of Your Life, the book walks the reader through building a straightforward ray tracing implementation from scratch.
While the book presents all of its code in C++, there have been countless others who have translated its content to other languages. Indeed, I am far from the first to attempt implementing the book on the GPU, but enjoyed the undertaking and decided to share my experience in doing so.
The books are available for a very reasonable $2.99 each on Amazon, and are freely (and legally) available here.
Motivation
Enjoyable challenge aside, the main motivation for moving this task to the GPU is speed. Ray tracing happens to fall into a category of problems sometimes referred to as “embarrassingly parallel”. Specifically, each individual pixel can be rendered separately without knowledge of other pixels being rendered alongside it. This is just the type of work a GPU is built for and will happily churn through with relative ease. A render that could take several minutes, if not hours, to create a passable image at low- to medium- resolution on a CPU, can produce a higher-quality result in a fraction of the time on a GPU.
“In an Afternoon”
The goal of this post is to summarize the changes involved to move the CPU-based implementation to run entirely on the GPU. It is assumed the reader is familiar with Shirley’s book, and has read through and followed along implementing the CPU-based ray tracer. The content here, then, should be largely review and it is not the goal to reintroduce concepts that are covered by the book.
It is recommended that the reader first work their way through the book’s implementation in order to gain a firm conceptual grasp before tackling a GPU-based implementation.
From start to finish, it took me only a few hours to implement the version of the book presented below, including searching for things like random number functions that aren’t immediately available GPU-side.
Setup
I used Visual Studio Code with the following plugins while implementing the ray tracer:
The ray tracer here is written in GLSL in order to take advantage of the Shader Toy plugin and get immediate feedback while working through the individual chapter implementations.
Adaptations
Inheritance and Polymorphism
In the book’s implementation, Shirley takes advantage of C++’s concepts of inheritance and polymorphism to present a clean and simple interface for hittable objects and materials to implement. This serves to simplify much of the implementation, as the implementer can then rely on the correct method being executed based on the underlying type.
For example:
classhittable{public:virtualboolhit(constray&r,floattmin,floattmax,hit_record&rec)const=0;};classsphere:publichittable{public:boolhit(constray&r,floattmin,floattmax,hit_record&rec)constoverride{// sphere-specific hit implentation}};
Since these commodities are not available on the GPU side, we can instead employ type identifiers when it’s necessary to be able to perform an action in a polymorphic way.
// MT_ material type#define MT_DIFFUSE 0
#define MT_METAL 1
#define MT_DIALECTRIC 2
structMaterial{inttype;vec3albedo;floatroughness;// controls roughness for metalsfloatrefIdx;// index of refraction for dialectric};boolscatter(RayrIn,HitRecordrec,outvec3atten,outRayrScattered){if(rec.material.type==MT_DIFFUSE){// ... diffuse scatter responsereturntrue;}if(rec.material.type==MT_METAL){// ... metal scatter responsereturntrue;}if(rec.material.type==MT_DIALECTRIC){// ... dialectric scatter responsereturntrue;}returnfalse;}
Random Numbers
C’s and C++’s random number utilities make random number generation CPU-side rather straightforward (we won’t discuss the merits of how “good” the results are here).
C++ provides the <random> header, and the types and functions therein can be used to easily generate random numbers in a given range. For our purposes, we’re specifically interested in generating numbers between 0 and 1.
While searching for an easy and “good enough” implementation of GPU-based pseudo-random numbers, I stumbled upon the following ShaderToy implementation by Reinder Nijhoff who adapted the hash functions by nimitz here. I also adopted the random_in_unit_disk and random_in_unit_sphere functions provided by Nijhoff. As mentioned in the introduction, I’m hardly the first to undertake this task.
Anti-aliasing
Chapter 7 of the book adds anti-aliasing to the ray tracer. At its very basics, this means taking multiple subsamples at a given pixel and averaging the results together. For my implementation of this chapter, I went with an absurdly simple box filter based implementation.
This works well enough to confirm that multiple subsamples averaged together make a cleaner image, but it’s limited in a number of ways, not the least of which is that the highly regular sampling pattern yields diminishing returns from additional samples.
Progressive Path Tracing
Starting with chapter 8, which introduces diffuse materials and kicks off what most would deem the more visually interesting portion of the book, I decided that instead of taking multiple samples per frame, I would instead create a feedback loop where all previous results were fed into the current frame. Each frame would use a random offset within the current pixel footprint by way of the noise functions mentioned earlier, and have its result appended to a running average of all previous frames.
The new shader entrypoint looks similar to the following, and is used in every subsequent chapter’s implementation.
// near the top of the shader - this is described in the Shader Toy plugin's documentation// sets the previous frame's result as a texture input to the current frame#iChannel0 "self"
Since the number of samples is ever-increasing, this approach has the potential to run into floating-point issues when the number of samples in the running average becomes large. If you remove the if(prev.w > 5000.0) block and allow the ray tracer to run long enough, you’re likely to see little black dots show up in the image. These are caused by values becoming so high in the running average that they are no longer representable as floating-point numbers and end up as nan or inf. Capping the number of samples allows for a high quality render and also avoids these issues. The value can be adjusted up or down depending on scene and preference. There are almost certainly more robust ways to solve this issue, but in the spirit of simplicity, that will be outside the scope of this post.
Because of the substantial speedup gained by moving the work to the GPU, I’ve added simple camera controls to the scenes. In cases where the camera moves, the running average is reset in order to prevent the views smearing across each other. This is what the if(iMouseButton...) check is doing.
Below are two images of the same scene, one taken moments after the render began, the other taken after a few seconds of accumulation.
Recursion
GLSL does not support recursive functions. This limitation is simple enough to overcome by instead using a loop with a capped number of steps.
The CPU implementation below, taken from my own initial follow-along with the book
The initial ray is simply overwritten with the result of the ray produced by the scattering event before the next loop iteration.
Scene Representation
The use of polymorphic types allows certain niceties as described in the section above. One of these niceties is having a HittableList type that can itself include any number of Hittable implementers and be traversed quite easily.
Instead of creating a pseudo-polymorphic hittable type as described above for materials, I’ve instead opted for building the scene on each invocation of a hit_world function that can be implemented freshly in each shader depending on what content is desired. There is perhaps a trade-off here between the memory usage and execution speed that could be worth exploring in the future. For a scene reprensentation built on shader entry and used throughout, the memory requirement would increase, but the cost of re-creating those types and materials during traversal may decrease.
Of course, there’s nothing stopping you from implementing a more flexible Hittable type, similar to how materials are handled, and having a type identifier decipher which intersection function should be used. For the purposes of this exercise, I found the above approach to be plenty.
The Code
Obtaining
All the code associated with this post can be found in the below GitLab repository. The code is structured such that there is one .glsl file for each chapter of the book that produces output. The files are named with a convention of b#_ch#.glsl where the first number is which book the file comes from, and the second is the chapter in the book. All of the first book in the series is represented, as well as the first chapter in the second book, as it was minimal effort to add a new MovingSphere type and implement motion blur.
The common.glsl file contains types, intersection functions, the scattering function, helper functions for creating types with default values, and the all-important noise functions.
The simplest way to see the code in action is to follow theses steps:
clone it from the repository
open a Visual Studio Code workspace at the root of the folder containing the code
open one of the chapter .glsl files
select Shader Toy: Show GLSL Preview from the VS Code command palette (ctrl+shift+p).
ShaderToy
With a little coercing, mostly around setting up the feedback-loop through a buffer, detecting mouse movement, and updating main to mainImage, the code can be updated to run on ShaderToy. I’ve created an example here.
In order to see the results in action, be sure to press the play button on the embedded viewer. Click and move the mouse to change the camera location.
I have recently been working on implementing a Vulkan 1.1 backend for my engine. Since the project started with a Direct3D 12 graphics backend, all of the shaders are written in HLSL. While DXC has done wonders to reduce the amount of rework needed for many of the project’s shaders, one feature that did not work directly out of the box when cross-compiling to SPIR-V for Vulkan was unbounded arrays of textures. There seems to be limited information available online about how to support these, so that will be the focus of this post.
To be clear, when I say “array of textures” I am talking about the following:
Texture2Dmytextures[10]:register(t0);// array of textures <- this post is about thisTexture2DArrayothertexture:register(t0);// texture array <- not talking about this
HLSL and Direct3D 12 allow for truly unbounded arrays of textures. The shader author does not need to know the upper limit of the array, and from the application side the implemeneter only needs to be sure they do not cause the shader to index outside of a valid range of bound descriptors. Since not indexing outside the bounds of an array is a characteristic of a well-formed application in the first place, this seems a reasonable requirement for the flexibility this introduces.
To be a bit more specific, here’s what we are trying to support in a cross-platform way:
// instead of thisTexture2DmaterialTextures[1024]:register(t0);// array of textures with upper limit// we want to write thisTexture2DmaterialTextures[]:register(t0);// unbounded array of textures
Error Messages
When initially starting a Vulkan build of the application without any of the required extended features enabled and an unbound array of textures in use by a shader, the first error we stumble upon is something similar to the following, let’s call this Error 1:
Shader requires VkPhysicalDeviceDescriptorIndexingFeaturesEXT::runtimeDescriptorArray but is not enabled on the device.
Easy enough, it tells us directly in the message which feature we need to enable in order for this syntax to be allowed. I’ll show later in the post how to query for support and enable that feature, but for now let’s move on. With that feature enabled, the initial error is assuaged, but now we have a new validation error, which we’ll refer to as Error 2:
Descriptor set 0x4c6 bound as set #1 encountered the following validation error at vkCmdDrawIndexed() time: Descriptor in binding #1 index 18 is being used in draw but has not been updated.
What this is basically saying is that if you have a descriptor set layout that declares itself has having some number of descriptors, but you have only written the first few descriptors into your descriptor set, and the shader could possibly index past where you have written, you are in error. Since we updated our shader and enabled the runtimeDescriptorArray feature, the validation layer assumes that the entire descriptor set could be accessed by the shader and will validate against the entire contents, including for locations that may not have actually been written.
For example, say our descriptor set layout declares that it uses 1000 descriptors, but so far we have only had need to load the first 100. The validation layer will see the uninitialized contents after our first 100 textures and think that we may intend to index into them in the shader, which would be an error. There is a fairly straightforward way around this without enabling another feature that I will show, but if the feature descriptorBindingPartiallyBound is available, I recommend enabling it as it will provide true support for partial binding.
Quick and Dirty Way to Address Error 2
All it boils down to is this. After the valid entries have been written into VkWriteDescriptorSet structs, fill the entirety of the remaining objects with the first descriptor. The only assumption made here is that at least the first descriptor is valid. I feel this is a safe-enough assumption when combined with some well-placed assertions, otherwise why make a call to update the set in the first place? This way technically works, insofar that draws take place as expected with no validation layer warnings.
// after cycling through all of the "real" descriptors desired to be set, find out if any descriptor slots are leftif(descriptorCount<descriptorRange.numDescriptors){// for each unwritten descriptor in the layout, copy the first descriptor into those locationsfor(uint32i=descriptorCount;i<descriptorRange.numDescriptors;++i){// the first descriptor is assumed to be validimageInfos[i]=imageInfos[0];++descriptorCount;}}VkWriteDescriptorSetwriteDescriptorSet;writeDescriptorSet.sType=VK_STRUCTURE_TYPE_WRITE_DESCRIPTOR_SET;writeDescriptorSet.pNext=nullptr;writeDescriptorSet.dstSet=descriptorSet;writeDescriptorSet.dstBinding=binding;writeDescriptorSet.dstArrayElement=0u;writeDescriptorSet.descriptorCount=descriptorCount;writeDescriptorSet.descriptorType=VK_DESCRIPTOR_TYPE_SAMPLED_IMAGE;writeDescriptorSet.pImageInfo=pImageInfo;writeDescriptorSet.pBufferInfo=nullptr;writeDescriptorSet.pTexelBufferView=nullptr;vkUpdateDescriptorSets(...);// as usual
Even with the extended feature enabled, filling in the remaining descriptors with a known error texture would be a good way of detecting out-of-bounds accesses at runtime. Thanks to Alex Tardif for bringing that to my attention.
A Cleaner Approach
The following approach solves both of the issues presented above, and is a simpler and cleaner approach compared to copying a single descriptor all over the place.
We want to query for and enable two extended features in order to enable truly unbounded arrays of textures. As luck would have it, both features come from the same set, namely VkPhysicalDeviceDescriptorIndexingFeaturesEXT. The features we want enabled are:
runtimeDescriptorArray - for Error 1
descriptorBindingPartiallyBound - for Error 2
This code block shows how to query for support for these features for a given VkPhysicalDevice:
VkPhysicalDeviceDescriptorIndexingFeaturesEXTindexingFeatures{};indexingFeatures.sType=VK_STRUCTURE_TYPE_PHYSICAL_DEVICE_DESCRIPTOR_INDEXING_FEATURES_EXT;indexingFeatures.pNext=nullptr;VkPhysicalDeviceFeatures2deviceFeatures{};deviceFeatures.sType=VK_STRUCTURE_TYPE_PHYSICAL_DEVICE_FEATURES_2;deviceFeatures.pNext=&indexingFeatures;vkGetPhysicalDeviceFeatures2(physicalDevice,&deviceFeatures);if(indexingFeatures.descriptorBindingPartiallyBound&&indexingFeatures.runtimeDescriptorArray){// all set to use unbound arrays of textures}
Next, enable those two features when creating the logical device (VkDevice):
VkPhysicalDeviceDescriptorIndexingFeaturesEXTindexingFeatures{};indexingFeatures.sType=VK_STRUCTURE_TYPE_PHYSICAL_DEVICE_DESCRIPTOR_INDEXING_FEATURES_EXT;indexingFeatures.pNext=nullptr;indexingFeatures.descriptorBindingPartiallyBound=VK_TRUE;indexingFeatures.runtimeDescriptorArray=VK_TRUE;VkDeviceCreateInfocreateInfo{};createInfo.sType=VK_STRUCTURE_TYPE_DEVICE_CREATE_INFO;createInfo.pNext=&indexingFeatures;// the rest of the createInfo is filled out as normal
The last adjustment we need to make is to the descriptor set layout. For layouts requiring an unbounded array of textures, we want to add the VK_DESCRIPTOR_BINDING_PARTIALLY_BOUND_BIT_EXT flag by filling out a VkDescriptorBindingFlagsEXT struct. This will allow the validation layer to ease up and trust that the implementer is not going to index outside the valid range of bound descriptors for the given set.
// update these values to be useful for your specific use caseVkDescriptorSetLayoutBindinglayoutBinding{};layoutBinding.binding=0u;layoutBinding.descriptorType=VK_DESCRIPTOR_TYPE_SAMPLED_IMAGE;layoutBinding.descriptorCount=10000u;layoutBinding.stageFlags=VK_SHADER_STAGE_FRAGMENT_BIT;VkDescriptorBindingFlagsEXTbindFlag=VK_DESCRIPTOR_BINDING_PARTIALLY_BOUND_BIT_EXT;VkDescriptorSetLayoutBindingFlagsCreateInfoEXTextendedInfo{};extendedInfo.sType=VK_STRUCTURE_TYPE_DESCRIPTOR_SET_LAYOUT_BINDING_FLAGS_CREATE_INFO_EXT;extendedInfo.pNext=nullptr;extendedInfo.bindingCount=1u;extendedInfo.pBindingFlags=&bindFlag;VkDescriptorSetLayoutCreateInfolayoutInfo{};layoutInfo.sType=VK_STRUCTURE_TYPE_DESCRIPTOR_SET_LAYOUT_CREATE_INFO;layoutInfo.pNext=&extendedInfo;layoutInfo.flags=0;layoutInfo.bindingCount=1u;layoutInfo.pBindings=&layoutBinding;vkCreateDescriptorSetLayout(...);// as usual
Final Thoughts
There you have it. The second way requires a little more initialization code at startup to query for and enable the required features, but that seems a small price to pay for a cleaner implementation and being able to bind partially-filled descriptor sets.
That said, it is also compatible with copying a known texture descriptor (error or otherwise) as mentioned earlier, if desired. Use cases vary across and within projects, and the implementer should choose the best fit for the problem they’re solving.
Being a sole developer, I don’t have access to the swaths of hardware configurations available to larger studios. I can however state that the above features are available on my 980 Ti, which is over four years old at the time of writing this post. I imagine most desktop GPUs will have had the features available for some time now, though mobile-centric GPUs may not be as accommodating (mobile is not currently one of my target ecosystems). Specific device support can be looked up on Sascha Willem’s site here.
]]>Will PearceA Platform-Independent Thread Pool Using C++142016-01-03T00:00:00-05:002016-01-03T00:00:00-05:00https://willpgfx.com/2016/01/a-platform-independent-thread-pool-using-c14
Introduction
One of the major benefits provided by the new generation of graphics APIs is much better support for multithreaded command list generation and submission. It’s not uncommon for computers nowadays to contain 2, 4, 8, or even 16 core processors. The goal of the solution in this post is to ensure we can use the power our CPU provides, not just for generating graphics command lists, but for any task that can be easily parallelized.
At its simplest, a thread pool is a collection of threads that run continuously waiting to take on a task to complete. If there’s no task available, they yield or sleep for some amount of time, wake back up, and check again. When a task is available, one of the waiting threads claims it, runs it, and returns to the waiting state.
The reason we would want to use a thread pool instead of creating new threads over and over for each task we want to run on a separate thread is to save on the time it would otherwise take to construct a thread, submit work to it, and deconstruct it when it’s done running. With a small collection of threads continuously running and waiting on tasks, we’re only left with the middle step - work submission.
Implementation
The thread pool presented here is based off the implementation provided in [1]. It has been updated to include variadic arguments for added flexibility.
A Thread-Safe Queue
Before we build the pool itself, we need a means of submitting work in a thread-safe manner. Jobs should be picked up in the same order they are submitted to the pool, which means a queue is a good candidate. Jobs are pushed to the back of the queue, and popped from the front.
/**
* The ThreadSafeQueue class.
* Provides a wrapper around a basic queue to provide thread safety.
*/#pragma once
#ifndef THREADSAFEQUEUE_HPP
#define THREADSAFEQUEUE_HPP
#include<atomic>
#include<condition_variable>
#include<mutex>
#include<queue>
#include<utility>namespaceMyNamespace{template<typenameT>classThreadSafeQueue{public:/**
* Destructor.
*/~ThreadSafeQueue(void){invalidate();}/**
* Attempt to get the first value in the queue.
* Returns true if a value was successfully written to the out parameter, false otherwise.
*/booltryPop(T&out){std::lock_guard<std::mutex>lock{m_mutex};if(m_queue.empty()||!m_valid){returnfalse;}out=std::move(m_queue.front());m_queue.pop();returntrue;}/**
* Get the first value in the queue.
* Will block until a value is available unless clear is called or the instance is destructed.
* Returns true if a value was successfully written to the out parameter, false otherwise.
*/boolwaitPop(T&out){std::unique_lock<std::mutex>lock{m_mutex};m_condition.wait(lock,[this](){return!m_queue.empty()||!m_valid;});/*
* Using the condition in the predicate ensures that spurious wakeups with a valid
* but empty queue will not proceed, so only need to check for validity before proceeding.
*/if(!m_valid){returnfalse;}out=std::move(m_queue.front());m_queue.pop();returntrue;}/**
* Push a new value onto the queue.
*/voidpush(Tvalue){std::lock_guard<std::mutex>lock{m_mutex};m_queue.push(std::move(value));m_condition.notify_one();}/**
* Check whether or not the queue is empty.
*/boolempty(void)const{std::lock_guard<std::mutex>lock{m_mutex};returnm_queue.empty();}/**
* Clear all items from the queue.
*/voidclear(void){std::lock_guard<std::mutex>lock{m_mutex};while(!m_queue.empty()){m_queue.pop();}m_condition.notify_all();}/**
* Invalidate the queue.
* Used to ensure no conditions are being waited on in waitPop when
* a thread or the application is trying to exit.
* The queue is invalid after calling this method and it is an error
* to continue using a queue after this method has been called.
*/voidinvalidate(void){std::lock_guard<std::mutex>lock{m_mutex};m_valid=false;m_condition.notify_all();}/**
* Returns whether or not this queue is valid.
*/boolisValid(void)const{std::lock_guard<std::mutex>lock{m_mutex};returnm_valid;}private:std::atomic_boolm_valid{true};mutablestd::mutexm_mutex;std::queue<T>m_queue;std::condition_variablem_condition;};}#endif
Most of this is pretty standard fare for designing a thread-safe class. We lock a mutex anytime we need to read or write data and provide a simplified interface over a std::queue where writes are checked for validity before being performed. This is why tryPop and waitPop return bools for success and write to the provide parameter in successful cases.
Any time push is called with a new task, it calls notify_one() on the condition variable which will wake one thread blocked on the condition. The mutex is locked, the predicate is checked, and if all conditions are met (the queue is not empty and the queue is still valid), a task is popped and returned from the queue.
Because this queue provides a blocking method, waitPop, that depends on a condition variable being set to continue, it also needs a way to signal to anything waiting on the condition in the case that the queue needs to be deconstructed while there are threads still blocked on the condition. This is accomplished through the invalidate() method that first sets the m_valid member to false and then calls notify_all() on the condition variable. This will wake up every thread blocked on the condition and waitPop will return with a value of false, indicating to the call site that no work is being returned.
Another nicety the condition variable gives us is protection from spurious wakeups [3]. If a spurious wakeup does occur and the entire predicate isn’t met, the thread goes back to waiting.
The Thread Pool
The implementation of the thread pool is shown below.
/**
* The ThreadPool class.
* Keeps a set of threads constantly waiting to execute incoming jobs.
*/#pragma once
#ifndef THREADPOOL_HPP
#define THREADPOOL_HPP
#include"ThreadSafeQueue.hpp"#include<algorithm>
#include<atomic>
#include<cstdint>
#include<functional>
#include<future>
#include<memory>
#include<thread>
#include<type_traits>
#include<utility>
#include<vector>namespaceMyNamespace{classThreadPool{private:classIThreadTask{public:IThreadTask(void)=default;virtual~IThreadTask(void)=default;IThreadTask(constIThreadTask&rhs)=delete;IThreadTask&operator=(constIThreadTask&rhs)=delete;IThreadTask(IThreadTask&&other)=default;IThreadTask&operator=(IThreadTask&&other)=default;/**
* Run the task.
*/virtualvoidexecute()=0;};template<typenameFunc>classThreadTask:publicIThreadTask{public:ThreadTask(Func&&func):m_func{std::move(func)}{}~ThreadTask(void)override=default;ThreadTask(constThreadTask&rhs)=delete;ThreadTask&operator=(constThreadTask&rhs)=delete;ThreadTask(ThreadTask&&other)=default;ThreadTask&operator=(ThreadTask&&other)=default;/**
* Run the task.
*/voidexecute()override{m_func();}private:Funcm_func;};public:/**
* A wrapper around a std::future that adds the behavior of futures returned from std::async.
* Specifically, this object will block and wait for execution to finish before going out of scope.
*/template<typenameT>classTaskFuture{public:TaskFuture(std::future<T>&&future):m_future{std::move(future)}{}TaskFuture(constTaskFuture&rhs)=delete;TaskFuture&operator=(constTaskFuture&rhs)=delete;TaskFuture(TaskFuture&&other)=default;TaskFuture&operator=(TaskFuture&&other)=default;~TaskFuture(void){if(m_future.valid()){m_future.get();}}autoget(void){returnm_future.get();}private:std::future<T>m_future;};public:/**
* Constructor.
*/ThreadPool(void):ThreadPool{std::max(std::thread::hardware_concurrency(),2u)-1u}{/*
* Always create at least one thread. If hardware_concurrency() returns 0,
* subtracting one would turn it to UINT_MAX, so get the maximum of
* hardware_concurrency() and 2 before subtracting 1.
*/}/**
* Constructor.
*/explicitThreadPool(conststd::uint32_tnumThreads):m_done{false},m_workQueue{},m_threads{}{try{for(std::uint32_ti=0u;i<numThreads;++i){m_threads.emplace_back(&ThreadPool::worker,this);}}catch(...){destroy();throw;}}/**
* Non-copyable.
*/ThreadPool(constThreadPool&rhs)=delete;/**
* Non-assignable.
*/ThreadPool&operator=(constThreadPool&rhs)=delete;/**
* Destructor.
*/~ThreadPool(void){destroy();}/**
* Submit a job to be run by the thread pool.
*/template<typenameFunc,typename...Args>autosubmit(Func&&func,Args&&...args){autoboundTask=std::bind(std::forward<Func>(func),std::forward<Args>(args)...);usingResultType=std::result_of_t<decltype(boundTask)()>;usingPackagedTask=std::packaged_task<ResultType()>;usingTaskType=ThreadTask<PackagedTask>;PackagedTasktask{std::move(boundTask)};TaskFuture<ResultType>result{task.get_future()};m_workQueue.push(std::make_unique<TaskType>(std::move(task)));returnresult;}private:/**
* Constantly running function each thread uses to acquire work items from the queue.
*/voidworker(void){while(!m_done){std::unique_ptr<IThreadTask>pTask{nullptr};if(m_workQueue.waitPop(pTask)){pTask->execute();}}}/**
* Invalidates the queue and joins all running threads.
*/voiddestroy(void){m_done=true;m_workQueue.invalidate();for(auto&thread:m_threads){if(thread.joinable()){thread.join();}}}private:std::atomic_boolm_done;ThreadSafeQueue<std::unique_ptr<IThreadTask>>m_workQueue;std::vector<std::thread>m_threads;};namespaceDefaultThreadPool{/**
* Get the default thread pool for the application.
* This pool is created with std::thread::hardware_concurrency() - 1 threads.
*/inlineThreadPool&getThreadPool(void){staticThreadPooldefaultPool;returndefaultPool;}/**
* Submit a job to the default thread pool.
*/template<typenameFunc,typename...Args>inlineautosubmitJob(Func&&func,Args&&...args){returngetThreadPool().submit(std::forward<Func>(func),std::forward<Args>(args)...);}}}#endif
There are a few pieces to touch on here. First, we have an IThreadTask interface that defines an execute() pure virtual function. The reason for this interface is simply so we can maintain a collection of them in one container type (the ThreadSafeQueue<T>). ThreadTask<T> implements IThreadTask and takes a callable type T for its template parameter.
When constructing the thread pool, we attempt to read the number of hardware threads available to the system by using std::thread::hardware_concurrency(). We always ensure the pool is started with at least one thread running, and ideally started with hardware_concurrency - 1 threads running. The reason for the minus one will be discussed later. For each thread available, we construct a std::thread object that runs the private member function worker().
The worker function’s only job is to endlessly check the queue to see if there is work to be done and execute the task if there is. Since we’ve taken care to design the queue in a thread-safe manner, we don’t need to do any additional synchronization here. The thread will enter the loop, get to waitPop, and either pop and execute a queued task, or wait on a task to become available via the submit function. If waitPop returns true, we know pTask has been written to and can immediately execute it. If it returns false, it most likely means that the queue has been invalidated.
The submit function is the public facing interface of the thread pool. It starts by creating a few handy type definitions that make the actual implementation easier to follow. First, the provided function and its arguments are bound to a callable object with no parameters using std::bind. We need this for our ThreadTask<T> class to be able to call execute on its functor without having to know the arguments that came with the original function. We then create a std::packaged_task with the bound task and extract the std::future from it before pushing it onto the queue. Here again, we do not need to do any additional synchronization due to the thread-safe implementation of the queue. You’ll notice the std::future returned from the std::packaged_task is wrapped in a class called TaskFuture<T>. This was a design decision because of the way I intend to use the pool in my specific application. I wanted the futures to mimic the way std::async futures work, specifically that they will block until their work is complete when they are going out of scope and being destructed. std::packaged_task futures don’t do this out of the box, so we give them a simple wrapper to emulate the behavior [2]. Like std::future, TaskFuture is movable-only, so the synchronization does not have to occur in the same method as the call site as long as it’s passed along from the method.
You will see where the queue’s invalidate method is called in the thread pool’s destroy() method, which is called from the destructor or if an exception is thrown while creating the threads in the constructor, before joining the threads, and after setting the thread pool’s done marker to true. The order is important to ensure that the threads know to exit their worker functions instead of re-attempting to obtain more work from the invalidated queue. Due to the way the predicate is set up on the queue’s condition variable, it is not an error to re-enter waitPop on an invalidated queue since it will just return false, but it is a waste of time.
An optional nicety I decided to throw in is the DefaultThreadPool namespace. This creates a thread pool with the maximum number of threads as discussed previously and is accessible from anywhere in the application that includes the thread pool header. I prefer using this as opposed to having each subsystem owning its own thread pool, but there’s nothing wrong with creating thread pool instances through the constructors, either.
Submitting Work to the Thread Pool
With the above in place. Submitting work is as simple as including the thread pools header file and calling its submit function with a callable object and optionally arguments to be provided to it.
To ensure the thread pool and backing queue work not only in ideal cases, but also in the case where work is being submitted faster than the threads can take it on, we can write a little program that submits a bunch of jobs that sleep for a while and then synchronizes on them. My machine reports eight as the result of std::thread::hardware_concurrency(), so I create a thread pool with seven threads. The task I’m running is just to sleep whatever thread is executing for one second and finish. I’ll submit twenty-one of these jobs to the pool. We know that this would take about twenty-one seconds if executed serially, and since we’re running a thread pool with seven threads, we know that if everything is working well the jobs should all complete in about three seconds.
Running the above code on my machine, the result is just about what would be expected, averaging around 3.005 seconds over a dozen runs.
About the Number of Pooled Threads
Earlier I mentioned that I start the thread pool with std::thread::hardware_concurrency() - 1 threads. The reason for this is simple. The thread that’s calling the thread pool is a perfectly valid thread to do work on while you’re waiting for the results of submitted tasks to become available. Despite the example from the Does It Work? section, submitting a bunch of jobs and then just waiting on them to complete is hardly optimal, so it makes sense to have the thread pool executing up to NumThreads - 1 jobs and the main thread doing whatever work it can accomplish in the meantime. Splitting the workload up evenly across all available threads is usually the best approach with a task-based setup like this.
Conclusion
This post has discussed what a thread pool is, why they’re useful, and how to get started implementing one. There are very likely ways to make the provided thread pool more performant by specializing it more to avoid memory allocations on job submissions, but for my use cases I typically ensure the jobs being submitted are large enough that they make up for the time lost to allocating and deallocating memory with the time gained by running them in parallel with other large tasks. Your mileage may vary, but at the very least you should have a solid start to customizing a thread pool to fit your exact needs.
Acknowledgements
Thank you to the members of /r/cpp who helped with code review and provided feedback.
References
[1] William, Anthony. C++ Concurrency in Action: Practical Multithreading. ISBN: 9781933988771
]]>Will PearceScreen Space Glossy Reflections Demo Available2015-12-16T00:00:00-05:002015-12-16T00:00:00-05:00https://willpgfx.com/2015/12/screen-space-glossy-reflections-demo-availableIt’s Been a While
Earlier this year I wrote a post discussing an implementation of real-time screen space glossy reflections. The post has received a lot of positive feedback, and I’ve had some very interesting conversations with various individuals since it went up discussing theory, details, shortcomings, and everything in between. The response has been great, and I appreciate the community’s interest. One request I’ve received a few times is for a working demo that users could play with to get a better feel for the effect in action. I had originally hoped to finish updating the engine to support DirectX 12 before releasing anything, and while it’s probably about 90% done, there are still some areas that need work and my time lately has been limited.
Thankfully, it’s the year 2015 (for a little while longer) and we have this magical thing called source control. I’ve decided to use a tag I created right before the DX 12 update began, and have modified it to provide a small demo for anyone that’s been waiting on it. The goods news is that it’s entirely DirectX 11-based, so the hardware support will be much broader than that of a DX 12 solution. The downside is that I’ve been able to make a few improvements, especially around blending missed ray hits with fallback solutions that won’t be present in the demo provided. I should get a chance to release a demo with the new features once things settle down a bit and all will be right with the world.
Demo Controls
Once the scene loads, anyone familiar with first person applications should feel more or less at home with the basics. A, W, S, and D control movement, with W and S moving the camera forwards and backwards, and A and D strafing the camera left and right. The mouse controls where the camera looks. The user is not glued to the ground, so will move forward in whatever direction the camera is facing. J and K control the floor roughness value, with J making the floor smoother, and K making it rougher. A uniform roughness texture is applied over the entire floor, but in a real-world application an artist-authored texture would be used to make the results much more convincing. Q and E are used to change the time of day.
The Esc key is used to quit the application. To restart the scene without exiting, use the left, right, or up arrow keys.
Some Ugliness
The fallback environment maps are setup exactly as they were in the original post. Specifically, this means that a large area of the scene only has the global, undetailed environment map to fall back to. This is quite noticeable in the beginning area of the scene underneath the characters. If you move directly forward from the starting point of the scene, you’ll pass through a few walls and end up in an enclosed hallway-type structure. This area does have localized environment maps to fallback to on ray hits and the results are cleaner. As stated in the first section, more work has been done to improve blending that is not present in the demo.
Besides the shortcomings of the screen space approach discussed in the original blog post, the stack of boxes in the scene still use the engine’s old physics and collision system. In the latest version, all of this has been updated to use the Bullet Physics implementation, but if you choose to knock the stack down (clicking the left mouse button throws a ball), be aware that you’re likely to see quite a bit of oddness. That being said - go for it, it’s always fun to knock things over!
Also, ambient light is handled by sampling from environment maps placed throughout the scene. To ensure maintaining these doesn’t become a bottleneck, only one is ever updated per frame, and they’re only updated when the lighting changes. Namely, this means that as the time of day changes the environment maps will get rebuilt. If the time of day changes slowly enough, as it would in a real-world application, these updates would be mostly unnoticeable. However, since the user can control the time of day the overall lighting situation can change faster than the environment maps can keep up. If the user holds down one of the keys to change the time of day, they’ll see stale lighting data being applied to most parts of the scene. Once the key is released, the environment map renderer will catch up and the lighting will become coherent again.
The Demo
Below is a link to download the demo. Feel free and encouraged to continue commenting, asking questions, and offering constructive criticism.
]]>Will PearceScreen Space Glossy Reflections2015-07-10T00:00:00-04:002015-07-10T00:00:00-04:00https://willpgfx.com/2015/07/screen-space-glossy-reflections
Introduction
Reflections are an important effect present in any routine attempting to approximate global illumination. They give the user important spatial information about an object’s location, as well as provide an important visual indicator of the surface properties of certain materials.
For several years now, engineers and researchers in real-time graphics have worked towards improving reflections in their applications. Simple implementations like cube maps used as reflection probes have been around for decades, while much newer techniques build upon their predecessors, such as parallax-corrected environment maps [4].
More recently, screen space ray tracing has become a widely used supplement to previously established methods of applying reflections to scenes. The idea is simple enough - a view ray is reflected about a surface normal, then the resultant vector is stepped along until it has intersected the depth buffer. With that location discovered, the light buffer is sampled and the value is added to the final lighting result. The below image shows a comparison of a scene looking at a stack of boxes without and with screen space ray tracing enabled.
In practice, there are more than a few pitfalls to this approach that need special care and addressing to avoid. The most obvious short-coming of this and any other screen space effect is the limited information available. If a ray doesn’t hit something before leaving the screen bounds, it will not return a result, even if its would-be collider is just barely off-screen.
This effect also tends to have a lot of trouble with rays facing back towards the viewer. When given thought, it makes a lot of sense that this would present an issue. For one, if the ray reflects directly back at the viewer, it will never intersect the depth buffer, thus basically degenerating into the case of rays traveling off-screen that’s already been discussed. The other issue is similar, but maybe not as obvious. If a ray is traveling back in the general direction of the viewer and it does intersect the depth buffer, it’s likely to do so on a face of an object that’s faced away from the viewer. This means that even if an intersection is reported, an incorrect result will be sampled from the light buffer at that position. This can lead to ugly artifacts such as streaks across surfaces. The figure below shows a top-down view of a ray being cast from the viewer, hitting a mirrored surface, and finally making contact with the back of a box. Since from the viewer’s perspective the back of the box is not currently on-screen, erroneous results will be returned if that result is used.
There are ways to mitigate many of these artifacts, including fallback methods and fading that will be addressed later on.
Glossy Ray Traced Reflections
One further challenge with the generic approach described above is that if the result is used directly, only perfectly mirror-like reflections can be generated. In the real world, most surfaces do not reflect light perfectly, but instead scatter, absorb, and reflect it in varying proportions due to microfacets [9]. To account for this, the technique needs to not only consider where the ray intersects the depth buffer, but also the roughness of the reflecting surface and the distance the ray has traveled. The following image shows a comparison of mirror-like and glossy reflections. Notice on the right half of the image how the further the ray has to travel to make contact, the blurrier it becomes.
The rest of this post will re-touch on some of these issues as it discusses and provides a full implementation of ray tracing in screen space and creating glossy reflections via cone tracing.
Setting Up
The effects described in this post are implemented using DirectX 11 and HLSL. That’s not at all to say those are mandatory for following along. In fact, the ray tracing shader used below is a translation of one written in GLSL, which would use OpenGL as its graphics API.
This implementation was designed as part of a deferred shading pipeline. The effect runs after geometry buffer generation and lighting has completed. The ray tracing step needs access to the depth buffer and a buffer containing the normals of the geometry in view. The blurring step needs access to the light buffer. The cone tracing step needs access to all of the aforementioned buffers, including the resultant ray traced buffer and blurred light buffer, as well as a buffer containing the specular values for materials in view. It is also beneficial to include a fallback buffer containing indirect specular contributions derived from methods such as parallax-corrected cube maps. These will each be addressed as they are used in the implementation.
Therefore, the final list of buffers needed before starting the effect becomes:
Depth buffer - the implementation uses a non-linear depth buffer due to its ready availability after the geometry buffer is generated. McGuire’s initial implementation [1] uses a linear depth buffer and may be more efficient.
Normal buffer - the geometry buffer used in this implementation stores all values in view space. If the implementer stores their values in world space, they will need to be cognizant of the differences and prepared to apply appropriate transforms when necessary.
Light buffer - this is a buffer containing all lighting to be applied to the scene. The exact values stored in this buffer will be refined further during implementation discussion.
Specular buffer - stored linearly as Fresnel reflectance at normal incidence (F(0°)) [5]. Some engines, such as Unreal Engine 4, have different workflows where this value may be hard-coded for dialectrics to a value of around 0.04 and stored in base color for metals. The engine in use for this project is custom and stores the value directly.
Roughness buffer - this engine stores the roughness value in the w-component of the specular buffer, and is thus readily available when the previous buffer is bound.
Fallback indirect specular buffer - this buffer contains specular lighting values calculated before the ray tracing step using less precise techniques such as parallax-corrected cube maps and environment probes to help alleviate jarring discontinuities between ray hits and misses.
The depth buffer used in this implementation has 32 bits for depth. All buffers containing lighting data contain 16 bit per channel floating point values.
Also needed for this effect is a constant buffer containing values specific to the effect. In the initial GLSL implementation these were passed as uniforms, but in HLSL we set up a constant buffer like so:
/**
* The SSLRConstantBuffer.
* Defines constants used to implement SSLR cone traced screen-space reflections.
*/#ifndef CBSSLR_HLSLI
#define CBSSLR_HLSLI
cbuffercbSSLR:register(b0){float2cb_depthBufferSize;// dimensions of the z-bufferfloatcb_zThickness;// thickness to ascribe to each pixel in the depth bufferfloatcb_nearPlaneZ;// the camera's near z planefloatcb_stride;// Step in horizontal or vertical pixels between samples. This is a float// because integer math is slow on GPUs, but should be set to an integer >= 1.floatcb_maxSteps;// Maximum number of iterations. Higher gives better images but may be slow.floatcb_maxDistance;// Maximum camera-space distance to trace before returning a miss.floatcb_strideZCutoff;// More distant pixels are smaller in screen space. This value tells at what point to// start relaxing the stride to give higher quality reflections for objects far from// the camera.floatcb_numMips;// the number of mip levels in the convolved color bufferfloatcb_fadeStart;// determines where to start screen edge fading of effectfloatcb_fadeEnd;// determines where to end screen edge fading of effectfloatcb_sslr_padding0;// padding for alignment};#endif
This constant buffer is contained in it’s own .hlsli file and included in the various steps where needed. Most of the values map directly to uniform values in the GLSL implementation, and a few others will be discussed as they become pertinent.
Ray Tracing in Screen Space
The ray tracing portion of this technique is directly derived from Morgan McGuire and Mike Mara’s open source implementation of using the Digital Differential Analyzer (DDA) line algorithm to evenly distribute ray traced samples in screen space [1]. Their method handles perspective-correct interpolation of a 3D ray projected to screen space, and helps avoid over- and under-sampling issues present in traditional ray marches. This helps more evenly distribute the limited number of samples that can be afforded per frame across the ray instead of skipping large portions at the start of the ray and bunching up samples towards the end.
McGuire and Mara’s initial implementation was presented in GLSL and assumed negative one (-1) to be the far plane Z value. Below, the implementation has been converted to HLSL and uses positive one for the far plane. The initial implementation also uses a linear depth buffer, though their accompanying paper provides source code for running the effect with a non-linear depth buffer. The provided implementation assumes non-linear depth, and reconstructs linear Z values as they are sampled from the depth buffer using the methods described in [6].
// By Morgan McGuire and Michael Mara at Williams College 2014// Released as open source under the BSD 2-Clause License// http://opensource.org/licenses/BSD-2-Clause//// Copyright (c) 2014, Morgan McGuire and Michael Mara// All rights reserved.//// From McGuire and Mara, Efficient GPU Screen-Space Ray Tracing,// Journal of Computer Graphics Techniques, 2014//// This software is open source under the "BSD 2-clause license"://// Redistribution and use in source and binary forms, with or// without modification, are permitted provided that the following// conditions are met://// 1. Redistributions of source code must retain the above// copyright notice, this list of conditions and the following// disclaimer.//// 2. Redistributions in binary form must reproduce the above// copyright notice, this list of conditions and the following// disclaimer in the documentation and/or other materials provided// with the distribution.//// THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND// CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES,// INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF// MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE// DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR// CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,// SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT// LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF// USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED// AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT// LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING// IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF// THE POSSIBILITY OF SUCH DAMAGE./**
* The ray tracing step of the SSLR implementation.
* Modified version of the work stated above.
*/#include"SSLRConstantBuffer.hlsli"
#include"../../ConstantBuffers/PerFrame.hlsli"
#include"../../Utils/DepthUtils.hlsli"Texture2DdepthBuffer:register(t0);Texture2DnormalBuffer:register(t1);structVertexOut{float4posH:SV_POSITION;float3viewRay:VIEWRAY;float2tex:TEXCOORD;};floatdistanceSquared(float2a,float2b){a-=b;returndot(a,a);}boolintersectsDepthBuffer(floatz,floatminZ,floatmaxZ){/*
* Based on how far away from the camera the depth is,
* adding a bit of extra thickness can help improve some
* artifacts. Driving this value up too high can cause
* artifacts of its own.
*/floatdepthScale=min(1.0f,z*cb_strideZCutoff);z+=cb_zThickness+lerp(0.0f,2.0f,depthScale);return(maxZ>=z)&&(minZ-cb_zThickness<=z);}voidswap(inoutfloata,inoutfloatb){floatt=a;a=b;b=t;}floatlinearDepthTexelFetch(int2hitPixel){// Load returns 0 for any value accessed out of boundsreturnlinearizeDepth(depthBuffer.Load(int3(hitPixel,0)).r);}// Returns true if the ray hit somethingbooltraceScreenSpaceRay(// Camera-space ray origin, which must be within the view volumefloat3csOrig,// Unit length camera-space ray directionfloat3csDir,// Number between 0 and 1 for how far to bump the ray in stride units// to conceal banding artifacts. Not needed if stride == 1.floatjitter,// Pixel coordinates of the first intersection with the sceneoutfloat2hitPixel,// Camera space location of the ray hitoutfloat3hitPoint){// Clip to the near planefloatrayLength=((csOrig.z+csDir.z*cb_maxDistance)<cb_nearPlaneZ)?(cb_nearPlaneZ-csOrig.z)/csDir.z:cb_maxDistance;float3csEndPoint=csOrig+csDir*rayLength;// Project into homogeneous clip spacefloat4H0=mul(float4(csOrig,1.0f),viewToTextureSpaceMatrix);H0.xy*=cb_depthBufferSize;float4H1=mul(float4(csEndPoint,1.0f),viewToTextureSpaceMatrix);H1.xy*=cb_depthBufferSize;floatk0=1.0f/H0.w;floatk1=1.0f/H1.w;// The interpolated homogeneous version of the camera-space pointsfloat3Q0=csOrig*k0;float3Q1=csEndPoint*k1;// Screen-space endpointsfloat2P0=H0.xy*k0;float2P1=H1.xy*k1;// If the line is degenerate, make it cover at least one pixel// to avoid handling zero-pixel extent as a special case laterP1+=(distanceSquared(P0,P1)<0.0001f)?float2(0.01f,0.01f):0.0f;float2delta=P1-P0;// Permute so that the primary iteration is in x to collapse// all quadrant-specific DDA cases laterboolpermute=false;if(abs(delta.x)<abs(delta.y)){// This is a more-vertical linepermute=true;delta=delta.yx;P0=P0.yx;P1=P1.yx;}floatstepDir=sign(delta.x);floatinvdx=stepDir/delta.x;// Track the derivatives of Q and kfloat3dQ=(Q1-Q0)*invdx;floatdk=(k1-k0)*invdx;float2dP=float2(stepDir,delta.y*invdx);// Scale derivatives by the desired pixel stride and then// offset the starting values by the jitter fractionfloatstrideScale=1.0f-min(1.0f,csOrig.z*cb_strideZCutoff);floatstride=1.0f+strideScale*cb_stride;dP*=stride;dQ*=stride;dk*=stride;P0+=dP*jitter;Q0+=dQ*jitter;k0+=dk*jitter;// Slide P from P0 to P1, (now-homogeneous) Q from Q0 to Q1, k from k0 to k1float4PQk=float4(P0,Q0.z,k0);float4dPQk=float4(dP,dQ.z,dk);float3Q=Q0;// Adjust end condition for iteration directionfloatend=P1.x*stepDir;floatstepCount=0.0f;floatprevZMaxEstimate=csOrig.z;floatrayZMin=prevZMaxEstimate;floatrayZMax=prevZMaxEstimate;floatsceneZMax=rayZMax+100.0f;for(;((PQk.x*stepDir)<=end)&&(stepCount<cb_maxSteps)&&!intersectsDepthBuffer(sceneZMax,rayZMin,rayZMax)&&(sceneZMax!=0.0f);++stepCount){rayZMin=prevZMaxEstimate;rayZMax=(dPQk.z*0.5f+PQk.z)/(dPQk.w*0.5f+PQk.w);prevZMaxEstimate=rayZMax;if(rayZMin>rayZMax){swap(rayZMin,rayZMax);}hitPixel=permute?PQk.yx:PQk.xy;// You may need hitPixel.y = depthBufferSize.y - hitPixel.y; here if your vertical axis// is different than ours in screen spacesceneZMax=linearDepthTexelFetch(depthBuffer,int2(hitPixel));PQk+=dPQk;}// Advance Q based on the number of stepsQ.xy+=dQ.xy*stepCount;hitPoint=Q*(1.0f/PQk.w);returnintersectsDepthBuffer(sceneZMax,rayZMin,rayZMax);}float4main(VertexOutpIn):SV_TARGET{int3loadIndices=int3(pIn.posH.xy,0);float3normalVS=normalBuffer.Load(loadIndices).xyz;if(!any(normalVS)){return0.0f;}floatdepth=depthBuffer.Load(loadIndices).r;float3rayOriginVS=pIn.viewRay*linearizeDepth(depth);/*
* Since position is reconstructed in view space, just normalize it to get the
* vector from the eye to the position and then reflect that around the normal to
* get the ray direction to trace.
*/float3toPositionVS=normalize(rayOriginVS);float3rayDirectionVS=normalize(reflect(toPositionVS,normalVS));// output rDotV to the alpha channel for use in determining how much to fade the rayfloatrDotV=dot(rayDirectionVS,toPositionVS);// out parametersfloat2hitPixel=float2(0.0f,0.0f);float3hitPoint=float3(0.0f,0.0f,0.0f);floatjitter=cb_stride>1.0f?float(int(pIn.posH.x+pIn.posH.y)&1)*0.5f:0.0f;// perform ray tracing - true if hit found, false otherwiseboolintersection=traceScreenSpaceRay(rayOriginVS,rayDirectionVS,jitter,hitPixel,hitPoint);depth=depthBuffer.Load(int3(hitPixel,0)).r;// move hit pixel from pixel position to UVshitPixel*=float2(texelWidth,texelHeight);if(hitPixel.x>1.0f||hitPixel.x<0.0f||hitPixel.y>1.0f||hitPixel.y<0.0f){intersection=false;}returnfloat4(hitPixel,depth,rDotV)*(intersection?1.0f:0.0f);}
The DepthUtils.hlsli header contains the linearizeDepth function that’s used to convert a perspective-z depth into a linear value. The PerFrame.hlsli header contains several values that are set at the start of a frame and remain constant throughout. Of particular interest are texelWidth and texelHeight, which contain the texel size for the client (1 / dimension). We use these value to convert pixel positions from the trace result into UV coordinates for easy lookup in subsequent steps.
An idea borrowed from Ben Hopkins (@kode80), who also open sourced his implementation of ray tracing based on McGuire’s initial work, is to use cutoff value for the stride based on Z distance [2]. The idea is that since as the distance grows further from the viewer and perspective projection makes objects smaller in screen space, the stride can be shortened and still likely find its contact point. This helps distant locations create higher quality reflections than if they were to use a large stride similar to closer locations. In the above implementation, this idea was extended into adding additional thickness to objects as their distance from the viewer increased. This resulted in less artifacts at shallow angles where the rayZMin and rayZMax values would grow such that the sampled sceneZMax would fail and be rejected by small margins.
Another interesting idea from Hopkins’ implementation was to store the values and the step derivatives in float4 types. The goal of this is to encourage the HLSL compiler to take advantage of SIMD operations since they are used in identical operations all at the same time. In practice, the output from the Visual Studio 2013 Graphics Debugger showed the bytecode was nearly identical between the McGuire implementation and Hopkins’ implementation, but it was left in for being a cool idea.
The image below shows the results of the ray tracing step. The buffer values include the UV coordinates of the ray hit in the x and y components, the depth in the z component, and the dot product of the view ray and the reflection ray in the w component. The value stored in the w-component is used in the cone tracing step to fade rays facing towards the camera. Black pixels mark areas where no intersection occurred.
Blurring the Light Buffer
The next step to obtaining glossy reflections is to blur the light buffer. Specifically, the light buffer is copied to the top-most mip level of a texture supporting a full mip chain, and from there the result is blurred into its lower mip levels. A separable 1-dimensional Gaussian blur is used. The below implementation uses a 7-tap kernel, but the implementer should experiment to get a value that seems appropriate for their particular needs. First the blur is applied vertically to a temporary buffer, then the blur is applied horizontally to the next level down in the mip chain. The following code listing shows a simple blur shader. Notice that to use the contents, there would need to exist two additional shaders, one defining each of the pre-processor directives specifying directionality and including the file below.
/**
* The Convolution shader body.
* Requires either CONVOLVE_VERTICAL or CONVOLVE_HORIZONTAL
* to be defined.
*/#ifndef CONVOLUTIONPS_HLSLI
#define CONVOLUTIONPS_HLSLI
#include"SSLRConstantBuffer.hlsli"structVertexOut{float4posH:SV_POSITION;float2tex:TEXCOORD;};Texture2DcolorBuffer:register(t1);#if CONVOLVE_HORIZONTAL
staticconstint2offsets[7]={{-3,0},{-2,0},{-1,0},{0,0},{1,0},{2,0},{3,0}};#elif CONVOLVE_VERTICAL
staticconstint2offsets[7]={{0,-3},{0,-2},{0,-1},{0,0},{0,1},{0,2},{0,3}};#endif
staticconstfloatweights[7]={0.001f,0.028f,0.233f,0.474f,0.233f,0.028f,0.001f};float4main(VertexOutpIn):SV_Target0{float2uvs=pIn.tex*cb_depthBufferSize;// make sure to send in the SRV's dimensions for cb_depthBufferSize// sample level zero since only one mip level is available with the bound SRVint3loadPos=int3(uvs,0);float4color=float4(0.0f,0.0f,0.0f,1.0f);[unroll]for(uinti=0u;i<7u;++i){color+=colorBuffer.Load(loadPos,offsets[i])*weights[i];}returnfloat4(color.rgb,1.0f);}#endif
During the blur passes the constant buffer values storing depth buffer size for the rest of the effect are re-purposed for recovering the load positions for fetches from the bound texture. At the end of all blur passes these values should be reset to the correct dimensions before proceeding.
Cone Tracing
At this point in the effect, the ray traced buffer is complete and the full mip chain of the light buffer has been generated. The idea in this section comes from the Yasin Uludag’s article in GPU Pro 5 [3].
It was mentioned earlier in the post that for glossy reflections to be represented, both the surface roughness and the distance traveled from the reflecting point to its point of contact needed to be accounted for. Whereas a perfect mirror would cast a straight line outwards from the origin point, a rougher surface would cast a cone shape. The figure below shows a representation of this phenomenon (albeit a bit crudely).
With these observation made, it can further be distinguished that in screen space a cone (3-dimensional) projects into an isosceles triangle (2-dimensional). Knowing the location of the starting point and the ray’s end point tells us how far in screen space the ray has traveled. With the roughness value available for the current surface through sampling the appropriate texture, everything that’s needed to move forward is on-hand.
The steps for cone tracing are as follows.
The adjacent length of the isosceles triangle is found by finding the magnitude of the vector from the origin position to the ray hit position.
The sampled roughness is converted into a specular power.
The specular power is then used to calculate the cone angle (theta) for the isosceles triangle.
The opposite length of the the triangle is found by dividing the cone angle in half and finding the opposite side of a right triangle using basic trigonometry, specifically that tan(theta) = oppositeLength/adjacentLength, which is equivalently represented as oppositeLength = tan(theta) * adjacentLength.
The result is then doubled to recover the full length.
The radius of a circle inscribed in the triangle is found using the formula found at [7] for isosceles triangles. This is used to determine the sample position and the mip level from which to sample.
The color is sampled and weighted based on surface roughness.
Steps 2-7 are repeated several times until the resulting alpha reaches 1, or the loop hits its iteration limit. During each iteration, the triangle’s adjacent length is shortened by the previously calculated radius, then each value is recomputed for the new triangle.
Step 7 in particular differs from Uludag’s implementation where he builds out an entire visibility buffer that is used to help diminish contributions from sampled pixels that should not be included as part of the result. For most cases, the results tend to be good enough with this simplified approach, and the cost saved from not creating the visibility buffer and the hierarchical z-buffer from Uludag’s article can be re-assigned to further refinements or other effects.
The formula for finding the incircle of an isosceles triangle is displayed below. In the formula, a represents the opposite length of the triangle and h represents the adjacent length. The following image was obtained from [7].
Once the cone traced color is found, it’s modulated by the calculated Fresnel term using the values from the specular buffer, a normalized vector pointing from the surface location back towards the viewer, and the surface normal. Finally, several fading steps are applied to help diminish the pronouncement of areas where the ray tracing step failed to find an intersection. The results of this step are added back to the original light buffer and the process is complete.
The below shader code demonstrates this process.
#include"SSLRConstantBuffer.hlsli"
#include"../../LightingModel/PBL/LightUtils.hlsli"
#include"../../ConstantBuffers/PerFrame.hlsli"
#include"../../Utils/DepthUtils.hlsli"
#include"../../ShaderConstants.hlsli"structVertexOut{float4posH:SV_POSITION;float3viewRay:VIEWRAY;float2tex:TEXCOORD;};SamplerStatesampTrilinearClamp:register(s1);Texture2DdepthBuffer:register(t0);// scene depth buffer used in ray tracing stepTexture2DcolorBuffer:register(t1);// convolved color buffer - all mip levelsTexture2DrayTracingBuffer:register(t2);// ray-tracing bufferTexture2DnormalBuffer:register(t3);// normal buffer - from g-bufferTexture2DspecularBuffer:register(t4);// specular buffer - from g-buffer (rgb = ior, a = roughness)Texture2DindirectSpecularBuffer:register(t5);// indirect specular light buffer used for fallback///////////////////////////////////////////////////////////////////////////////////////// Cone tracing methods///////////////////////////////////////////////////////////////////////////////////////floatspecularPowerToConeAngle(floatspecularPower){// based on phong distribution modelif(specularPower>=exp2(CNST_MAX_SPECULAR_EXP)){return0.0f;}constfloatxi=0.244f;floatexponent=1.0f/(specularPower+1.0f);returnacos(pow(xi,exponent));}floatisoscelesTriangleOpposite(floatadjacentLength,floatconeTheta){// simple trig and algebra - soh, cah, toa - tan(theta) = opp/adj, opp = tan(theta) * adj, then multiply * 2.0f for isosceles triangle basereturn2.0f*tan(coneTheta)*adjacentLength;}floatisoscelesTriangleInRadius(floata,floath){floata2=a*a;floatfh2=4.0f*h*h;return(a*(sqrt(a2+fh2)-a))/(4.0f*h);}float4coneSampleWeightedColor(float2samplePos,floatmipChannel,floatgloss){float3sampleColor=colorBuffer.SampleLevel(sampTrilinearClamp,samplePos,mipChannel).rgb;returnfloat4(sampleColor*gloss,gloss);}floatisoscelesTriangleNextAdjacent(floatadjacentLength,floatincircleRadius){// subtract the diameter of the incircle to get the adjacent side of the next level on the conereturnadjacentLength-(incircleRadius*2.0f);}///////////////////////////////////////////////////////////////////////////////////////float4main(VertexOutpIn):SV_TARGET{int3loadIndices=int3(pIn.posH.xy,0);// get screen-space ray intersection pointfloat4raySS=rayTracingBuffer.Load(loadIndices).xyzw;float3fallbackColor=indirectSpecularBuffer.Load(loadIndices).rgb;if(raySS.w<=0.0f)// either means no hit or the ray faces back towards the camera{// no data for this point - a fallback like localized environment maps should be usedreturnfloat4(fallbackColor,1.0f);}floatdepth=depthBuffer.Load(loadIndices).r;float3positionSS=float3(pIn.tex,depth);floatlinearDepth=linearizeDepth(depth);float3positionVS=pIn.viewRay*linearDepth;// since calculations are in view-space, we can just normalize the position to point at itfloat3toPositionVS=normalize(positionVS);float3normalVS=normalBuffer.Load(loadIndices).rgb;// get specular power from roughnessfloat4specularAll=specularBuffer.Load(loadIndices);floatgloss=1.0f-specularAll.a;floatspecularPower=roughnessToSpecularPower(specularAll.a);// convert to cone angle (maximum extent of the specular lobe aperture)// only want half the full cone angle since we're slicing the isosceles triangle in half to get a right trianglefloatconeTheta=specularPowerToConeAngle(specularPower)*0.5f;// P1 = positionSS, P2 = raySS, adjacent length = ||P2 - P1||float2deltaP=raySS.xy-positionSS.xy;floatadjacentLength=length(deltaP);float2adjacentUnit=normalize(deltaP);float4totalColor=float4(0.0f,0.0f,0.0f,0.0f);floatremainingAlpha=1.0f;floatmaxMipLevel=(float)cb_numMips-1.0f;floatglossMult=gloss;// cone-tracing using an isosceles triangle to approximate a cone in screen spacefor(inti=0;i<14;++i){// intersection length is the adjacent side, get the opposite side using trigfloatoppositeLength=isoscelesTriangleOpposite(adjacentLength,coneTheta);// calculate in-radius of the isosceles trianglefloatincircleSize=isoscelesTriangleInRadius(oppositeLength,adjacentLength);// get the sample position in screen spacefloat2samplePos=positionSS.xy+adjacentUnit*(adjacentLength-incircleSize);// convert the in-radius into screen size then check what power N to raise 2 to reach it - that power N becomes mip level to sample fromfloatmipChannel=clamp(log2(incircleSize*max(cb_depthBufferSize.x,cb_depthBufferSize.y)),0.0f,maxMipLevel);/*
* Read color and accumulate it using trilinear filtering and weight it.
* Uses pre-convolved image (color buffer) and glossiness to weigh color contributions.
* Visibility is accumulated in the alpha channel. Break if visibility is 100% or greater (>= 1.0f).
*/float4newColor=coneSampleWeightedColor(samplePos,mipChannel,glossMult);remainingAlpha-=newColor.a;if(remainingAlpha<0.0f){newColor.rgb*=(1.0f-abs(remainingAlpha));}totalColor+=newColor;if(totalColor.a>=1.0f){break;}adjacentLength=isoscelesTriangleNextAdjacent(adjacentLength,incircleSize);glossMult*=gloss;}float3toEye=-toPositionVS;float3specular=calculateFresnelTerm(specularAll.rgb,abs(dot(normalVS,toEye)))*CNST_1DIVPI;// fade rays close to screen edgefloat2boundary=abs(raySS.xy-float2(0.5f,0.5f))*2.0f;constfloatfadeDiffRcp=1.0f/(cb_fadeEnd-cb_fadeStart);floatfadeOnBorder=1.0f-saturate((boundary.x-cb_fadeStart)*fadeDiffRcp);fadeOnBorder*=1.0f-saturate((boundary.y-cb_fadeStart)*fadeDiffRcp);fadeOnBorder=smoothstep(0.0f,1.0f,fadeOnBorder);float3rayHitPositionVS=viewSpacePositionFromDepth(raySS.xy,raySS.z);floatfadeOnDistance=1.0f-saturate(distance(rayHitPositionVS,positionVS)/cb_maxDistance);// ray tracing steps stores rdotv in w component - always > 0 due to check at start of this methodfloatfadeOnPerpendicular=saturate(lerp(0.0f,1.0f,saturate(raySS.w*4.0f)));floatfadeOnRoughness=saturate(lerp(0.0f,1.0f,gloss*4.0f));floattotalFade=fadeOnBorder*fadeOnDistance*fadeOnPerpendicular*fadeOnRoughness*(1.0f-saturate(remainingAlpha));returnfloat4(lerp(fallbackColor,totalColor.rgb*specular,totalFade),1.0f);}
The following image roughly illustrates the process. From top to bottom, the floor of the image starts off perfectly mirror-like and gradually becomes rougher. The red lines indicate the cones. The circles inscribed in them show how the radii are used for mip selection (i.e., the larger the circle, the further down the mip chain), and the center of each circle is where the sample would be taken. Notice that for a perfectly mirror-like surface, the cone diminishes to a straight line.
Bringing It All Together
It’s mentioned earlier that a fallback technique is useful for any screen space reflection technique. This implementation uses parallax-corrected cube maps based on Lagarde’s post [4]. These also include a fallback to generic, non-corrected cube maps as a last resort. These values are all computed before the screen space reflections technique starts and are accessed above in the cone tracing step through the “indirectSpecularBuffer” resource. While fallback methods won’t be as exact as ray traced results, properly set-up cube maps can certainly help alleviate jarring artifacts. The image below shows a comparison of two sections of the same scene. The left half of the image does not have good cube map placement and the missed reflection data is quite noticeable under the sphere. The right half includes blended parallax-corrected cube maps and introduces a much less severe penalty for missed rays.
Another artifact of inadequate fallback techniques can also be seen in the left image above. As the traced ray nears closer to the edge of the screen, it starts to become faded. The code for this is towards the bottom of the cone tracing shader. Without a decent fallback technique in place, the differences between the center of the screen and the edges can be quite drastic. The right half of the image shows such fading only to a very minor degree, most noticeably on the left edge of the picture.
Due to the numerous issues mentioned towards the start of the post, rays facing back towards the viewer are disallowed entirely. This is an implementation choice and by no means a requirement. Implementers should experiment with their own scenes and determine whether backwards-traversing rays provide acceptable results for use cases specific to the application. In the implementation above, ray results start to fade as they become perpendicular such as to not cause a sharp cutoff at any one point.
A final nicety that was added to this implementation is that the indirect specular buffer is actually a part of the light buffer during the initial convolution and is subtracted back out before applying the cone tracing pass. What this allows for is metals to be reflected more appropriately in the cone traced step. In the image below, the left half does not take these steps into consideration and the metal’s reflection is black. The specular highlight shows up in the reflection since it is contributed from direct lighting, the sun in this case, but none of the indirect light is included. In the right half of the image, these effects are enabled and the sky is observable in the reflected sphere.
The U-shape on the bottom of each sphere is due to not having good fallback techniques in this area of the scene, and can be alleviated as discussed previously.
Areas of Improvement
The biggest area of needed improvement with this technique in its current state is the need for a better blur technique. The current separable Gaussian blur, while fast, can lead to reflections being blurred onto parts of the scene where they don’t belong. A feature-aware blur similar to a bilateral blur is likely a better candidate in this space. Specifically, the blur will likely need to account for large depth discrepancies and reject samples that do not fall within a specified threshold. It should be noted that battling these type of artifacts is a potential strength of Uludag’s proposed visibility buffer.
The blur can also be sped up while still obtaining the same results by using the approach found at [10]. This is slated as future work for the current effect.
While testing storage for the blurred results, a Texture2DArray was also tried out. While this means of storage improved the overall perceived smoothness of the blur over varying roughness values, the memory requirements and increased time to run the blur several times over the full textures were simply not worth the small improvements. The mip-chained texture provides decent results and blends adequately with trilinear sampling. While testing values for various kernel sizes and sigmas, the calculator at [11] was extremely helpful for quick iteration.
One further improvement that can be made to the blurred result using the current implementation is to sample several points within the inscribed circle instead of just the center and blend all the results together. The trade-off for sampling multiple points in this fashion is between performance and quality. This technique is demonstrated in [8] on page 3 of the conversation.
Another area of improvement for this technique would be to update the reflection model to better match the lighting model used in the rest of the engine’s rendering pipeline. As mentioned previously, the above implementation for the cone-tracing step is based off Uludag’s explanation provided in [3]. In its current state, the effect uses an approximation of the Phong model, while the rest of the pipeline uses GGX for its specular distribution term. Uludag does offer suggestions in his article on how to adapt to other reflection models, and this may be the topic of a future post once implemented.
Furthermore, using more efficiently packed buffers for lighting data could prove to be a performance improvement for this technique. As mentioned above, all buffers containing lighting data are 64-bit floating point buffers with 16 bits of precision in each channel. Future experimentation with a more efficient 32-bit floating point buffer such as DirectX’s DXGI_FORMAT_R11G11B10_FLOAT should be considered.
Results
This section contains images generated using the techniques described above. Each image is comprised of a few smaller images showing increasing roughness in the floor material.
The first image shows the effect working on a large scale in an area of the scene spanning over 100 meters.
The second image shows the effect working in a more localized setting at ground level, similar to how a user would perceive the world in a first-person game or application. The area uses parallax-corrected cube maps as a fallback technique, and missed ray intersections, such as those that would likely occur around concave objects (the soldier in this case), are very well-blended.
The third image again shows the effect in a localized setting. The later time of day creates a steeper contrast between shadowed and un-shadowed areas causing the effect to be more pronounced and better showing how a rougher surface will blur and even start to pull the reflection vertically.
The fourth image again uses a steeper lighting contrast to help demonstrate how the effect applies as the floor material changes from very smooth to very rough.
The following videos show the effect running in a real-time interactive application. For best viewing, it is recommended to either run the videos in full-screen with high-definition enabled, or visit their respective YouTube pages by following these links:
This post has presented a full implementation of a solution for glossy screen space reflections. While the abundance of programmer art and MS Paint images may not be quite as fantastical as those rendered using a proper studio’s asset collection, the contributions of the effect to the final result should be clear. Even with a basic reflection model, the technique serves to add more realism to a scene and provides a means for believable real-time reflections for rough surfaces.
Acknowledgements
I first came into contact with Bruce Wilkie about a year ago when he posted a topic on gamedev.net. We were both working on implementing Yasin Uludag’s article from GPU Pro 5 [3]. We spoke a few times on the subject, and it became abundantly clear that he was much more knowledgeable on the matter than me. He was critical in helping me understand and figure out Uludag’s use of the hierarchical Z-buffer for ray tracing and work the kinks out of my initial attempts at implementing it [8]. Bruce was kind enough to offer that we keep in touch and that I could ask him questions around issues I might have while implementing different features in my engine, which I work on as a hobby in my spare time. I’ve certainly taken advantage of that offer over the course of the year, and he’s offered various ranges of advice on almost everything graphics-related that’s been posted to this blog to date. He has shown a great deal of patience in helping clarify certain concepts to me, and has a knack for explaining how to arrive at a solution without simply giving the answer away - an extremely valuable teaching technique. He also brought the idea of the more efficient blur using [10] to my attention as a solid alternative to the standard approach used above, as well as offered a few more suggestions for improvement over the first draft of this post.
Thank you, Bruce.
I would also like thank Morgan McGuire (@morgan3d) and Mike Mara for open-sourcing and generously licensing their DDA-based ray tracing code. A thank you goes to Ben Hopkins (@kode80) for doing the same with his implementation.
]]>Will PearceDealing with Shadow Map Artifacts2015-05-10T00:00:00-04:002015-05-10T00:00:00-04:00https://willpgfx.com/2015/05/dealing-with-shadow-map-artifacts
In a previous post on stack stabilization, the linked video showed a few major issue with shadow mapping. These issues have plagued the technique since it’s inception, and while there are many methods that assist in alleviating them, it’s still very difficult to completely get rid of them. Here we’ll review some common artifacts and discuss potential ways to squash them.
Perspective Aliasing
These types of artifacts are perhaps the simplest to alleviate. Stair-like artifacts outlining the projected shadows are generally caused by the resolution of the shadow map being too low. Compare the halves in the image below. The top half shows a scene using a shadow map resolution of 256x256, while the bottom shows the same scene using a resolution of 2048x2048.
Unfortunately, increasing the resolution will only get us so far. Even at high resolutions, if the viewer is close enough to the receiving surface, tiny stair-like artifacts will still be noticeable along the edges of projected shadows. The solution to this is to use a technique called percentage closer filtering (PCF). Instead of sampling at one location, this algorithm samples several points around the initial location, weighs the results that are shadowed versus non-shadowed, and creates soft edges for the result. The image below shows an up-close view of a shadow map with 2048x2048 resolution without and then with PCF enabled.
There are several different sampling patterns that can be used for the PCF algorithm. Currently, I’m using a simple box filter around the center location. Other sampling patterns, such as a rotated Poisson disc, are also popular and produce varying results.
Shadow Acne
Another common artifact found in shadow mapping is shadow acne, or erroneous self-shadowing. This generally occurs when the texel depth in light space and the texel depth in view space are so close that floating point errors incorrectly cause the depth test to fail. The image below shows an example of these artifacts present (top) and addressed (bottom).
There are a few ways to address this issue. It’s so prevalent, that most graphics APIs provide a means to instantiate a rasterizer state that includes both a depth bias and a slope-scaled depth bias. Essentially, during shadow map creation, these values are used in combination to offset the current value by a certain amount and push it out of the range where floating point inaccuracies would cause inaccurate comparisons. One must be careful when setting these bias values. Too high of a value can cause the next issue to be discussed, peter panning, while too low of a value will still let acne artifacts creep back into the final image.
Peter Panning
It’s frustrating when introducing a fix for one thing breaks something else. That’s exactly what we can potentially end up with when we use depth biases for shadow maps. Peter Panning is caused by offsetting the depth values in light space too much. The result is that the shadow becomes detached from the object casting it. The image below displays this phenomenon. In both halves of the image, the blocks are resting on the ground, but in the top half the depth bias is so large that it pushes the shadow away from the caster, causing them to appear as though they could be floating. The bottom half uses a more appropriate depth bias and the shadow appears properly attached.
Bangarang!
Working in the Shader
Using hardware depth biasing in the rasterizer is nice in that it’s fast and easy enough to set up and get working. Sometimes, however, we have different needs for our shadow maps and want to delay these types of correction steps until further in the pipeline. Though I’ve since reverted to a more basic approach, when first implementing transmittance through thin materials I switched my shadow map vertex shaders to output linear values to make the implementation a bit more straightforward. If I used the rasterizer state offsets as described above, I would have to somehow track and undo those offsets before I could use the values effectively in my transmittance calculations, or else have major artifacts from depth discrepancies. Fortunately, there are several excellent resources that describe alternative methods for getting rid of shadow artifacts (see references), and with a combination of ideas borrowed from all of them, I’ve been able to get a fairly decent implementation working. Below is some example code in HLSL.
Storing linear values to the shadow map:
// client codeMatrix4x4flinearProjectionMtx=createPerspectiveFOVLHMatrix4x4f(fovy,aspect,nearPlane,farPlane);linearProjectionMtx.rc33/=farPlane;linearProjectionMtx.rc34/=farPlane;// shadow map vertex shaderfloat4main(VertexInvIn):SV_POSITION{// transform to homogeneous clip spacefloat4posH=mul(float4(vIn.posL,1.0f),worldViewProjectionMatrix);// store linear depth to shadow map - there is no change to the value stored for orthographic projections since w == 1posH.z*=posH.w;returnposH;}
Using a scaled normal offset in the light shader before transforming a point in world space by the shadow transform matrix. I use a deferred shading pipeline and store data in the G-Buffer in view space, hence having to transform the new position by the inverse of the camera view matrix first:
Once the point has been transformed by the shadow matrix, finish projecting it and apply a depth offset:
// complete projection by doing division by wshadowPosH.xyz/=shadowPosH.w;shadowPosH.z-=cb_depthBias*smTexelDimensions;floatdepth=shadowPosH.z;// depth to use for PCF comparison
And that’s it. The values for depth bias and normal offset have to be adjusted per light and depend on various factors, such as the light range, the shadow projection matrix, and to some extent the resolution of the shadow map, but when properly set the results can be quite nice and artifacts are almost entirely mitigated.
]]>Will PearceStacks on Stacks2015-05-08T00:00:00-04:002015-05-08T00:00:00-04:00https://willpgfx.com/2015/05/stacks-on-stacksA long while back, I realized my scenes would be better served and more interesting if there was a more dynamic component to them. Outside of the very basics, implementing a proper physics engine with accurate collision detection and response was quite foreign to me. Therefore, I picked up Ian Millington’s book Game Physics Engine Development and got to work. I enjoyed the author’s approachable writing style and well-explained information on both particle and rigid body dynamics. Within about a week or so, I was able to integrate a fairly robust adaptation of the engine presented in the book into my own engine’s architecture.
While the information presented on physical body simulation is quite good, the book’s main shortcoming is in collision detection and resolution. In fairness, the author calls this out and tries to realistically set the reader’s expectations, but there’s a lot left to be desired when two boxes can’t reliably be stacked on top of one another due to non-converging solutions for contact generation and impulse resolutions. Regardless, this is the approach that had lived in my engine for well over a year and still remains in the code base, although I consider it to be deprecated for anything beyond very simple simulations.
After a lot of research and a short back and forth email exchange with Randy Gaul, I tried my hand at implementing a more complex collision detection routine. The new routine generated an entire contact manifold, as opposed to the old one, which only ever recorded one contact between two objects for any given point in time. The contact manifold contained up to 4 points per collision pair. This data, combined with a few other tricks I picked up here and there, finally allowed a small stack of boxes to sit on top of each other without shaking and falling over.
Eventually, I decided I wanted an overall more robust solution for both physics simulation and collision detection and resolution, so I spent a weekend integrating the Bullet Physics library into my engine. Bullet’s API has proven to be reasonably straightforward, and I was able to get a stable stack of boxes set up in a very short amount of time.
The video below shows the dramatic difference in the old collision resolution method, and the newly implemented engine backed by Bullet.
With the old setup, I would place objects in the world with a sleep state and a tiny amount of space between each to give the appearance of a stack, but as soon as I interacted with anything in the stack, all bets were off. With the new implementation, I can safely let objects fall into place and rest on top of each other at the start of the simulation without worrying too much about the whole thing going haywire.
(Regarding the ugly shadow artifacts in the video, those will be addressed in a follow-up post specific to the topic.)
]]>Will PearceBachelor Thesis Acknowledgement2015-05-04T00:00:00-04:002015-05-04T00:00:00-04:00https://willpgfx.com/2015/05/bachelor-thesis-acknowledgementI recently received an acknowledgement in Lukas Hermanns’ bachelor’s thesis entitled Screen Space Cone Tracing for Glossy Reflections, which I thought was really cool of him. He’s produced some great results, and I’m happy to have lent a hand in the excellent work he’s done.
]]>Will PearceSeparable Subsurface Scattering2015-04-18T00:00:00-04:002015-04-18T00:00:00-04:00https://willpgfx.com/2015/04/separable-subsurface-scatteringI’ve recently implemented Screen-Space Separable Subsurface Scattering into my rendering engine. This implementation is based off the incredible work that’s been done over the past several years, and documented here and here. I’m quite pleased with the results I’m getting from the effect and so am posting a few screenshots of it in action.
The first screenshots show the effect in daylight. Hopefully it’s quite obvious which head in the picture has the new technique applied and which is being lit with the engine’s standard lighting model.
The second screenshot shows another part of the overall effect, which is the transmittance of light through very thin slabs of materials, such as ears.
The next screenshot better shows both subsurface scattering and transmittance working together. In particular, notice how the light behaves along the ridge of the nose.
Finally, I cobbled together a quick setup showing how this technique could be used to create a nice effect for candles. To make the effect, I added a wax-like kernel, and just aimed a bright spotlight straight down at a cylinder.
]]>Will PearceHello, World!2011-07-19T00:00:00-04:002011-07-19T00:00:00-04:00https://willpgfx.com/2011/07/hello-worldThis is a test post with a little sample code to verify syntax highlighting is working correctly.





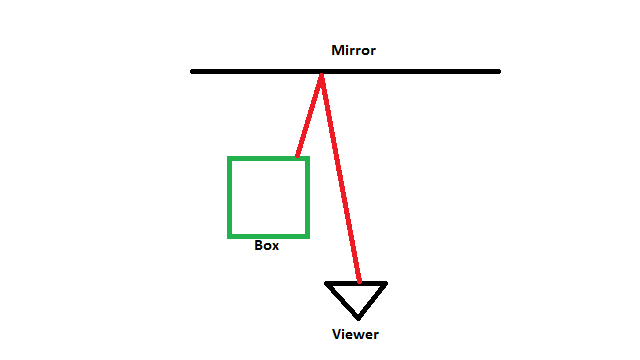

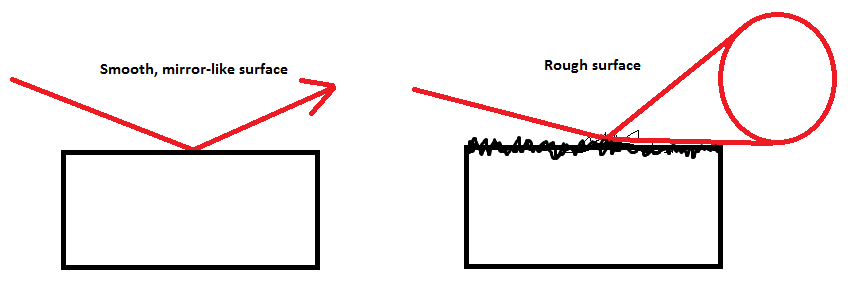
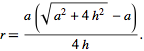
















{kind=link}